


Let’s start with the basic fundamentals of AI. What better place to start than the origins of the term “Artificial Intelligence”.
History Lesson
1956 – The Dartmouth Conference: The Dartmouth Summer Research Project on Artificial Intelligence was a seminal event for artificial intelligence as a field and is widely accepted as the coining of the term “Artificial Intelligence”.

> Human: Define “artificial intelligence”
> HAL: Artificial Intelligence (AI) refers to the development of computer systems that can perform tasks that typically require human intelligence. It is a broad field of study that encompasses various subfields, such as machine learning, natural language processing, computer vision, and robotics.

While this milestone was the beginning of “AI” as we know it, the concept has been around for much longer. In fact, greek mythology suggests a concept of “intelligent automata” back in BC times. They called it “Talos”. Talos was a bronze autonomous robot that circled the island of Crete three times a day to protect them from invaders. That’s the “Talos” backstory for Cisco’s threat intelligence group of modern day cyber security threat hunters and protectors.
Now, let’s see how this amazing field of study has evolved over the last 50+ years.
AI Milestones
1958 – Perceptron: Frank Rosenblatt developed the perceptron, a type of neural network capable of learning and making decisions based on inputs. It was one of the earliest examples of machine learning.
1966 – ELIZA: Developed by Joseph Weizenbaum, ELIZA was a computer program that simulated conversation using simple pattern matching and substitution rules. It demonstrated the potential of natural language processing and human-computer interaction.
1972–1976 – MYCIN: Stanford’s rule-based medical diagnosis system, one of the earliest expert systems, demonstrated that domain knowledge could be encoded as explicit rules. Never deployed clinically, but enormously influential.
1980s – Expert Systems Commercialization: R1/XCON, deployed by Digital Equipment Corporation around 1980–1982, became the first commercially successful expert system, saving DEC an estimated $40M annually and kicking off the expert systems industry boom.
1997 – Deep Blue: IBM’s Deep Blue chess-playing computer defeated world chess champion Garry Kasparov. It showcased the potential of AI in strategic decision-making and marked a significant achievement in machine learning and game-playing algorithms.
2006 – Deep Learning: Geoff Hinton and his team made breakthroughs in deep learning algorithms, particularly in training deep neural networks using large amounts of data. This paved the way for significant advancements in computer vision and speech recognition.
2011 – Watson: IBM’s Watson system competed and won against human champions on the quiz show “Jeopardy!” Watson demonstrated advancements in natural language processing, information retrieval, and machine learning.
2012 – ImageNet: The ImageNet Large Scale Visual Recognition Challenge revolutionized computer vision by introducing large-scale datasets for object recognition. Convolutional neural networks (CNNs), such as AlexNet, achieved groundbreaking accuracy and marked a turning point in image classification tasks.
2014 – Generative Adversarial Networks (GANs): Ian Goodfellow introduced GANs, a framework for training generative models. GANs have since been used for tasks like image synthesis, style transfer, and data augmentation.
2016 – AlphaGo: DeepMind’s AlphaGo defeated world champion Go player Lee Sedol. It showcased the power of reinforcement learning and marked a significant milestone in AI, as Go was considered a game requiring high-level human intuition.
2018 – Natural Language Processing: OpenAI’s GPT (Generative Pre-trained Transformer) model made significant strides in natural language processing tasks, such as text generation, language translation, and question-answering.
2020 – GPT-3: OpenAI released GPT-3, a highly advanced language model capable of generating coherent and contextually relevant text. GPT-3 showcased the potential of large-scale language models and raised awareness about ethical considerations surrounding AI.
2020 – Microsoft T-NLG: Microsoft introduced its Turing Natural Language Generation (T-NLG), which was then the “largest language model ever published at 17 billion parameters.” As well as an Open Source project called DeepSpeed.
2022 -GPT-3.5: While it gains considerable praise for the breadth of its knowledge base, deductive abilities, and the human-like fluidity of its natural language responses. It also garners criticism for, among other things, its tendency to “hallucinate“, a phenomenon in which an AI responds with factually incorrect answers with high confidence. The release triggers widespread public discussion on artificial intelligence and its potential impact on society.
2023 – GPT-4: Unlike previous iterations, GPT-4 is multimodal, allowing image input as well as text. GPT-4 is integrated into ChatGPT as a subscriber service. OpenAI claims that in their own testing the model received a score of 1410 on the SAT (94th percentile), 163 on the LSAT (88th percentile), and 298 on the Uniform Bar Exam (90th percentile).
2023 – Google Bard: In response to ChatGPT, Google releases in a limited capacity its chatbot Google Bard, based on the LaMDA family of large language models, in March 2023. Update: Bard is now called “Gemini”
I’m going to paraphrase Al from the Deadpool movies.

“Listen to the PAST, it’s both a history teacher and a fortune teller”.
So, that brings us to current (at the time of writing, June 2023) affairs. However, before we talk about the future of AI. I’d like to take a slight detour.
Let’s discuss key fundamentals and the nomenclature of modern AI systems.
Note:
This article was originally written in June 2023. In most fields, that’s a footnote. In AI, that’s a lifetime. The timeline above captures the foundations accurately, but the three years since have been among the most consequential in the history of the field. Consider this section the “what happened next” chapter.
2023 (Post-June): The Open Source Earthquake
While ChatGPT and GPT-4 dominated headlines, Meta quietly released Llama 2 in July 2023, an open-weights model that anyone could download, modify, and deploy. This was the equivalent of handing out blueprints for a jet engine. Suddenly, researchers, startups, and enterprises didn’t need a subscription to a frontier lab to build serious AI applications. Mistral, a French AI company, followed in September with a model that punched well above its weight class on a fraction of the compute. The monopoly on capability started to crack.
2024: The Year AI Got Eyes, Ears, and a Memory
Google rebranded Bard to Gemini in February 2024, signaling a full-stack AI pivot. Gemini 1.5 Pro launched with a context window of one million tokens, meaning it could read and reason over an entire codebase, a book, or hours of video in a single pass. For context, GPT-3 had a context window of roughly 4,000 tokens. The jump in memory capacity alone reshaped what was possible.
OpenAI released GPT-4o in May 2024, the “o” standing for omni. It could see, hear, and speak in real time, responding to tone of voice and facial expressions with latency that felt genuinely conversational. The barrier between AI and natural human interaction got noticeably thinner.
Anthropic’s Claude 3 family arrived in March 2024 with three tiers: Haiku (fast and lean), Sonnet (balanced), and Opus (frontier performance). Claude 3 Opus outperformed GPT-4 on several benchmarks at launch. The message was clear: OpenAI was no longer the only name in the room.
Sora, OpenAI’s text-to-video model, previewed in February 2024 and went public in December. Type a sentence, get a cinematic video clip. The generative models that started with text, moved to images, then to code, had now reached motion picture.
2024 (Fall): AI That Thinks Before It Answers
In September 2024, OpenAI released o1, a model that introduced a fundamentally different behavior: deliberate reasoning before responding. Previous models generated answers token by token in a single forward pass. o1 was trained to pause, work through a chain of thought, check its own reasoning, and then respond. Think of the difference between someone who blurts out the first answer that comes to mind and someone who sketches out the problem on paper before speaking. o1 and its successor o3 perform dramatically better on mathematics, coding, and scientific reasoning as a result.
2025: Efficiency Rewrites the Rules
In January 2025, DeepSeek R1 landed and the AI industry sat up straight. A Chinese AI lab had built a reasoning model that matched or exceeded the performance of OpenAI’s o1 on key benchmarks, at a fraction of the training cost. Where frontier American models required hundreds of millions of dollars in compute, DeepSeek R1 was built for roughly $6 million. It was released as open weights. The assumption that raw compute spend was the only path to frontier performance got a serious stress test that day.
Agentic AI: From Answering Questions to Taking Action
Perhaps the most significant shift of 2024 to 2025 isn’t a single model release but a behavioral one. AI systems began moving from answering questions to completing tasks. Agentic AI can browse the web, write and run code, manage files, send emails, and chain together multi-step workflows with minimal human intervention. The model isn’t just a consultant anymore. It’s becoming a colleague. Tools like Cursor transformed software development. AI coding assistants moved from autocomplete to architecture. The question shifted from “what can AI tell me?” to “what can AI do for me?”
Where Things Stand in 2026
The field has more serious players than ever: OpenAI, Anthropic, Google DeepMind, Meta, Mistral, DeepSeek, and a long tail of open-source contributors all pushing the frontier simultaneously. Models are faster, cheaper, more capable, and more accessible than anyone predicted in June 2023. The AGI debate, once comfortably theoretical, is now a boardroom conversation at the labs building these systems.
The fundamentals covered in this article still hold. The transformer architecture still dominates. RLHF still shapes model behavior. RAG still powers enterprise applications. What has changed is the speed, the scale, the competition, and the ambition. If 2023 was the moment the world realized what AI could do, 2024 and 2025 were the years it started doing it.
The history teacher and the fortune teller are still the same person. We’re just living deeper in the story now.
Nomenclature of Modern AI Systems:
AI can be classified into two categories:
Narrow AI (weak AI) systems are designed to perform specific tasks, such as facial recognition, voice assistants, or recommendation algorithms.
General AI (strong AI) refers to highly autonomous systems that possess the ability to understand, learn, and apply knowledge across a wide range of tasks, similar to human intelligence. General AI remains an area of ongoing research and development.
The AI from 2001: A Space Odyssey, called Heuristically programmed ALgorithmic computer (HAL) 9000 is an example of General AI.
If you play video games, you will know there’s no shortage of DUMB non-player characters (NPCs). Some are so dumb they only can perform a single task (like walking or doing the same thing over and over). That’s an example of a Narrow AI and my youngest son loves when I go into “dumb NPC” mode in a public setting. My wife on the other hand, hates it.

AI Learning
Models: Remember my example of Talos the Greek autonomous robot protector? Now imagine if that robot didn’t have a brain and it was just a shell. An AI model is similar to the human brain. We want the robot to circle the island three times every day and look for invaders. Once it detects these invaders, it must engage and fight them off to protect the island. These actions are Talos instructions or goals. Without the brain/model (a special kind of computer program that can learn and make decisions to accomplish its goals), we wouldn’t have the necessary logic to carry out the automated tasks Talos was intended for. A model must be trained. Training the AI model is similar to teaching the human brain.
1) Show the model images of the pirate invaders and teach it that these are part of its instructions, they are what you are protecting the island against.
2) Keep feeding it more and more images so the accuracy of the actual pirates is high and the chance for misclassification/identification is low.
3) Continue to teach the model just as we would teach a human brain by feeding it more information over time.
Over time, the accuracy and confidence levels increase and we decrease the risk of misclassification. Once the model is trained, it becomes really good at these specific tasks linked to its goals and instructions. Over time the model will learn from new examples and optimize performance on what it has learned.
Machine Learning (ML): Machine learning refers to the subfield of AI. Focused on developing algorithms and models that enable computers to learn from data and make predictions or decisions without explicit programming.
It includes techniques such as supervised learning, unsupervised learning, and reinforcement learning.
- Supervised Learning: In supervised learning, models are trained on labeled data, where each input is associated with a corresponding target output. The model learns to map inputs to outputs by optimizing a loss function, aiming to minimize the discrepancy between predicted and true outputs.
- Unsupervised Learning: Unsupervised learning involves training models on unlabeled data. The goal is to discover underlying patterns, structures, or representations within the data. Common unsupervised learning techniques include clustering, dimensionality reduction, and generative modeling.
- Reinforcement Learning: Reinforcement learning focuses on training agents to make sequential decisions in an environment to maximize cumulative rewards. Agents learn through trial and error, receiving feedback in the form of rewards or penalties for their actions. Reinforcement learning often employs techniques such as value functions, policies, and exploration-exploitation trade-offs.
Neural Networks (NN): Neural networks are computing systems inspired by the structure and function of the human brain. They consist of interconnected nodes (similar to neurons) organized in layers and are used to recognize patterns, make predictions, and perform other AI tasks.
Generative Adversarial Network (GAN): A type of machine learning framework that consists of two neural networks, namely a generator network and a discriminator network, that work in tandem to generate and evaluate data.
The generator and discriminator networks are trained together in a competitive process. As training progresses, the generator aims to improve its ability to generate realistic data that can fool the discriminator, while the discriminator strives to become more accurate in distinguishing between real and fake data.
Deep Learning (DL): Deep learning is a subset of machine learning that utilizes artificial neural networks with multiple layers to extract high-level representations from raw data. Deep learning has been particularly successful in computer vision, natural language processing, and speech recognition tasks.
Transfer Learning: Transfer learning is an approach in machine learning where knowledge acquired from one task or domain is utilized to improve performance on a different but related task or domain. It allows models to leverage pre-trained weights and knowledge, reducing the need for extensive training on new data.
Generative Models (aka Gen AI or Generative AI): Generative models are AI models that learn the underlying probability distribution of a given dataset to generate new samples that resemble the original data. They have been used for tasks such as image synthesis, text generation, and music composition.
Large language Models (LLMs): Advanced AI systems designed to understand and generate human-like text. They are trained on vast amounts of text data and use complex algorithms to process and manipulate language.
These models are called “large” because they have millions or even billions of parameters, which are like little switches that control how the model works. The more parameters a model has, the more complex and powerful it becomes.
Multimodality: Refers to the ability of a model to process and understand multiple types of input data such as text, images, audio, and video at the same time or interchangeably. Like a human can see and talk at the same time.
Foundational Models: These models aren’t just trained for one task, but can be adapted to many.
Think of them as Swiss Army knives of AI, trained broadly and adaptable for many downstream tasks with minimal additional training.
Natural Language Processing (NLP): Natural language processing focuses on enabling computers to understand, interpret, and generate human language. It involves tasks such as language translation, sentiment analysis, named entity recognition, and chatbots.
Computer Vision (CV): Computer vision involves the development of algorithms and systems that enable computers to understand and interpret visual data, such as images and videos. It encompasses tasks like object detection, image recognition, and image segmentation.
Finally, how can we adjust or guide a model’s behavior? There are actually four primary mechanisms worth understanding.
1) Fine-Tuning: adjusts a model’s internal weights so it specializes in a specific task or domain. This fundamentally changes the model itself! You’re essentially continuing the training process on a narrower, curated dataset. Fine-tuning is how you take a general-purpose model and make it deeply fluent in, say, medical terminology or legal contracts.
2) RLHF (Reinforcement Learning from Human Feedback): is the mechanism that transformed raw language models into the helpful, conversational assistants you interact with today. After initial training, human reviewers rate the model’s outputs, and those ratings are used to train a separate “reward model.” The original model is then fine-tuned using reinforcement learning to maximize that reward, essentially teaching it to prefer responses that humans find helpful, safe, and accurate. Without RLHF, GPT-4 would be an extraordinarily capable text predictor that had no particular interest in being useful or honest. RLHF is why it feels like a collaborator instead of an autocomplete engine. This is one of the most consequential developments in modern AI and deserves its own entry in any fundamentals primer.
3) RAG (Retrieval-Augmented Generation): allows a model to reach outside its trained knowledge and pull in real-time or proprietary information at inference time. Instead of baking all knowledge into the model’s weights during training, RAG connects the model to an external knowledge base, a database, a document library, a live search index, and injects relevant retrieved content into the prompt before the model generates its response. This is how enterprise AI systems answer questions about your company’s internal data without having to retrain the entire model. It’s also how you prevent a model from hallucinating answers to questions about events that happened after its training cutoff.
4) Prompting: provides clear instructions within the input itself to guide behavior without touching the model at all. This method changes what the model receives, not what the model is. System prompts, persona instructions, few-shot examples, and chain-of-thought directives all fall here. ChatGPT’s custom “GPTs” are a good example. They’re largely system prompts that establish context, tone, and constraints before the conversation begins.
To summarize: during the training phase, an AI model is exposed to a large dataset, learning patterns and relationships by adjusting its internal parameters to minimize errors. But training is just the foundation. RLHF shapes the model’s values and communication style. Fine-tuning specializes it for a domain. RAG extends its knowledge beyond what it was trained on. And prompting guides its behavior in real time. All four levers matter, and understanding which one to reach for is one of the most practical skills in working with modern AI systems.
Transformers Changed EVERYTHING!

TLDR: Transformers allow AI systems to understand context at scale by processing information in parallel, which is why modern AI suddenly became faster, smarter, and far more capable.
Transformers allow AI systems to understand context at scale by processing information in parallel, which is why modern AI suddenly became faster, smarter, and far more capable.
Up until the late 2010s, most AI systems processed information one step at a time. Models would read text sequentially, word by word, much like a human reading a sentence left to right. This worked, but it was slow, inefficient, and limited in how much context the model could truly understand at once.
Transformers changed that. If you are looking for a deep dive on this subject, check out “Attention is all you need” –Vaswani et al [2017]
Instead of processing information sequentially, transformer-based models look at everything at the same time. They can evaluate relationships between words, sentences, or even images simultaneously, allowing the model to understand context, nuance, and meaning far more effectively. This shift made it possible for AI systems to reason over long documents, hold coherent conversations, and generate responses that feel surprisingly human.
This architectural breakthrough unlocked something equally important: SCALE!
Transformers are highly parallelizable, which means they can efficiently run on modern GPUs and accelerators. As a result, researchers could train models on massive datasets using billions (and now trillions) of parameters. This is why today’s AI systems didn’t just get better, they got dramatically better.
Large Language Models (LLMs), multimodal systems, and foundational models all rely on transformer architectures at their core. Whether an AI system is writing code, analyzing images, generating video, or carrying on a conversation, there’s a very good chance a transformer is doing the heavy lifting behind the scenes.
In short, transformers didn’t just improve AI, they redefined what was possible. They are the backbone of modern AI systems in 2025 and beyond, and they’re the reason today’s models feel less like tools and more like collaborators.
AI Inference
Once the model is trained, it can be deployed for inference. In this phase, the model takes new, unseen input data and applies the learned patterns and rules to generate predictions or outputs. The input data can be in various formats, such as images, text, audio, or numerical values, depending on the specific task the model is designed for.
The inference process involves feeding the input data into the AI model, which then processes the data through its complex algorithms and neural network layers. The model produces an output or prediction based on its learned knowledge and the patterns it recognizes in the input data.
Inference is a crucial step in applying AI models to real-world problems, as it allows the models to generalize their learned knowledge to new, unseen data and provide useful predictions or outputs for decision-making or further actions.
If training is like teaching a student, inference is like testing them with new questions.
AI Prompts
> Human: define an AI prompt
> HAL: An AI prompt, also known as an instruction or query, refers to the input given to an AI system to generate a specific response or perform a desired task. It serves as a starting point or guidance for the AI model to understand the user’s intent and generate a relevant output.
Prompt engineering: Crafting well-formed and precise instructions, is an important aspect of working with AI models to achieve desired results. By providing clear and explicit prompts, users can effectively communicate their intentions and guide the AI model’s behavior.
Here’s a great infographic (provided by Nvidia) on AI and the key elements we discussed.
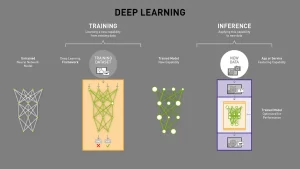
Human Intelligence (HI) vs Artificial Intelligence (AI)

Artificial General Intelligence (AGI): AGI refers to highly autonomous AI systems that possess general intelligence similar to human intelligence. While AGI is still a hypothetical concept, its potential impact, if realized, could be profound to the human race. Keep in mind, that according to some schools of thought AGI in 2026 is either imminent or already achieved by some definitions. This framing is still under active debate and revisions.
Now let’s not get ahead of ourselves just yet. You see, we humans still have several advantages (for now) vs AI.
Human Intelligence (HI) vs. Artificial Intelligence (AI)
So we’ve established that AI is extraordinary. It can read a million documents overnight, identify cancer in a scan faster than a radiologist, and beat the world’s best players at the most complex games humans ever invented. It’s easy to look at that list and start feeling like a slow, outdated piece of hardware.
Not so fast.
There’s a reason the most advanced AI systems on the planet were built by humans and not the other way around, and it isn’t just a head-start advantage. Let’s talk about what we actually bring to the table.
Creativity, Innovation, and Abstract Thinking. AI is extraordinarily good at recombining what it has seen. Ask it to write a poem and it will produce something that looks like poetry, sounds like poetry, and scans like poetry, because it has read every poem ever published. But the poet who wrote something that had never been thought before, who reached into an entirely new metaphor for grief or joy or war… that came from somewhere AI hasn’t been yet. Human creativity doesn’t just remix. It leaps. It makes connections across domains that have no business being connected, and somehow the connection is true.
Emotional Intelligence. A model can recognize the words you use when you’re sad. It can even mirror the tone back to you in a way that feels comforting. But it has never lost anyone. It has never sat in a hospital waiting room at 2am. Emotional intelligence isn’t just pattern recognition on human behavior. It’s the byproduct of having lived inside a human experience. That depth still belongs to us.
Common Sense and Contextual Understanding. Here’s a simple test. If I tell you “I saw a man on a hill with a telescope,” you intuitively know there’s ambiguity there. You understand the sentence could mean three different things, and you’d probably ask me which one I meant. Early AI systems would have picked one interpretation and committed to it with complete confidence. Modern LLMs do much better, but common sense, the kind that navigates a world full of unstated rules, unspoken social contracts, and physical reality, is still something humans develop through years of embodied experience that no training dataset fully captures.
Ethics and Moral Reasoning. This one is particularly important. AI systems can be taught to prefer certain outputs over others through techniques like RLHF, human feedback shaping the model’s behavior. But that’s borrowed ethics. It’s a reflection of our values, not an independently reasoned moral framework. When a genuinely novel ethical dilemma appears, one that has no clear precedent in the training data, the model has no bedrock to stand on. Humans do. We argue about ethics precisely because we take it seriously enough to disagree. That friction is a feature, not a bug.
Adaptability. A chess engine that can beat any human alive will not generalize that skill to checkers without being retrained. It is the undisputed best in the world at exactly the thing it was built for, and nothing else. Humans wake up every day in a world that didn’t send us a patch notes update, and we figure it out anyway. We change jobs, learn new skills, move to new cities, and adapt to circumstances that no one could have predicted. That fluid, general adaptability is something AI is actively trying to approach, and hasn’t reached yet.
Intuition and Insight. Some of the most important decisions in engineering, medicine, and science were made by someone who looked at the data and felt something was wrong before they could prove it. Call it pattern recognition operating below the threshold of conscious articulation. Call it experience crystallized into instinct. Whatever it is, it has saved lives and produced breakthroughs. AI doesn’t have hunches. It has probabilities.
Brain-to-Body Connection, Dexterity, and Sensory Perception. Robotics is advancing fast, but ask a state-of-the-art robotic hand to pick up a grape without crushing it, then pick up a hammer, then thread a needle. A three-year-old can do all three. The sensorimotor integration between the human brain and body, the feedback loops, the proprioception, the real-time calibration across thousands of micro-adjustments, is a mechanical and neurological marvel that engineering is still working hard to approximate.
And then there’s energy efficiency, which deserves its own moment. The human brain runs on roughly 20 watts. That’s less than the bulb in your refrigerator. It handles vision, language, emotion, memory, motor control, creativity, and consciousness simultaneously, all on the power budget of a dim nightlight. Compare that to the hardware side of AI: a single Nvidia A100 GPU draws 250 to 400 watts depending on the variant. Training ChatGPT required approximately 30,000 of them. At the conservative 250W figure, that’s 7.5 megawatts, just for the GPUs. Add the servers, the networking, and the HVAC required to keep all of that from melting, and you’re looking at a number that would make a power utility engineer sit up straight. The human brain is, by any measure, the most energy-efficient general-purpose computing system ever observed. We just tend to forget that when we’re impressed by what the expensive hardware can do.
So no, AI is not a replacement. It is a remarkable, rapidly improving tool. But the human beings building it, guiding it, correcting it, and deciding what it should be used for? We’re still the most interesting part of the story.
I’d like to leave you with one closing thought on HALs AI fundamental primer.
If Sci-Fi becomes a reality and AGI moves past the realm of theory. We might be able to ask HAL for the answer to “the ultimate question of life, the universe and everything”, do you think we are going to get this response or something more intriguing?
> HAL: The answer to the ultimate question of life, the universe and everything is… 42!
